12 Hours Running a Slay the Spire 2 AI: the Levers That Worked, and the Ones That Didn't
Slay the Spire 2 is a luck-heavy game where you pick cards, fight enemies, and climb to higher floors. I turned it into a program (a bot) that plays it for you, unattended (in part 1, I built the groundwork for observing and controlling the game from Python). The work of improving it — “how do we make it stronger?” — I handed to an AI (Claude Code) and let it run nonstop for about 12 hours.
There are plenty of “levers” you could pull to make it stronger: how hard it defends, how it picks cards, how it uses items. Which one actually moves the needle? Here are three conclusions from those 12 hours, up front.
- Tweaking the config numbers changed its strength not at all. I tried every knob I could think of, and they all came out flat.
- Only one thing worked: rebuilding the “procedure” for how it fights within a single turn. That alone roughly halved the damage it took per fight and doubled how deep it could climb.
- Even so, I couldn’t get past the wall of beating the first major boss reliably. Going further probably needs a different approach.
First: how I checked whether it “got stronger”
When you improve the bot, how do you confirm it actually “got stronger than before”? This turned out to be quietly hard.
Luck weighs heavily in this game, so even with the exact same strategy, how high it climbs is different every time. Sometimes it happens to reach far; sometimes it dies early. On top of that, at this point the bot has never once won. So I can’t compare with “win rate.”
So I decided to measure strength by “how far it climbed.” I run a new candidate and the current strongest version alternately, dozens of times each, and compare the distribution of floors reached. Alternating keeps “the conditions of the day” — time of day, a game update — from quietly favoring just one side. I only promoted a candidate when it clearly came out ahead.
If this “yardstick” were sloppy, everything that follows would have been nothing more than wishful thinking.
The levers that didn’t work: tweaking numbers moves nothing
The first thing I reached for was the config numbers. For example, “once HP drops this low, prioritize defense over attack” — I’d raise and lower that “threshold.” Or how highly to value strong cards, or how loosely to allow item use. I tried six such knobs, everything I could think of.
The result: all flat. The clincher was when I stacked every promising adjustment together — “the works.” Astonishingly, it came out not one millimeter different from the original play (even statistically, the test reported “identical”).
Why won’t it move? Going through the play logs, I kept finding kinds of “bad play” that no number could fix:
- Losing without ever using a powerful item (potion). It would hold two to four trump cards like “20 damage” or “Block +12” and die every time with them still in hand.
- Against a boss, defending endlessly and never closing out the kill. Even when focusing on offense would have finished the enemy, it got tied up with defense cards and went down first.
- At a rest site, always just picking the top option. It never chose between “upgrade a card” and “heal HP” by situation — the same mechanical pick no matter how many times I ran it.
No amount of number-tweaking fixes this fundamental bad play. Adding feature on top of feature, the root problem — “it just keeps getting whittled down” — never changed.
The lever that worked: not the numbers, but rebuilding the “play procedure”
Here I changed tack. The thing to touch isn’t the numbers. I rebuilt “what to do, and in what order” within a single turn.
The idea is almost anticlimactically straightforward:
- First, if there’s an enemy you can kill, kill it first. (one less source of incoming damage)
- Next, defend just enough to block the incoming attack — no more. (don’t over-defend)
- Pour everything left into attacking.
In short: “defend only as much as you need, then hit.” That’s all it is. And this was the improvement that won, clearly, for the first time.
- Damage taken per fight: average 13.4 → 7.1 (roughly half)
- Depth reached (median): 7.5 → 15.5 (double)
- Even compared statistically, it came out as “a difference chance can’t explain.”
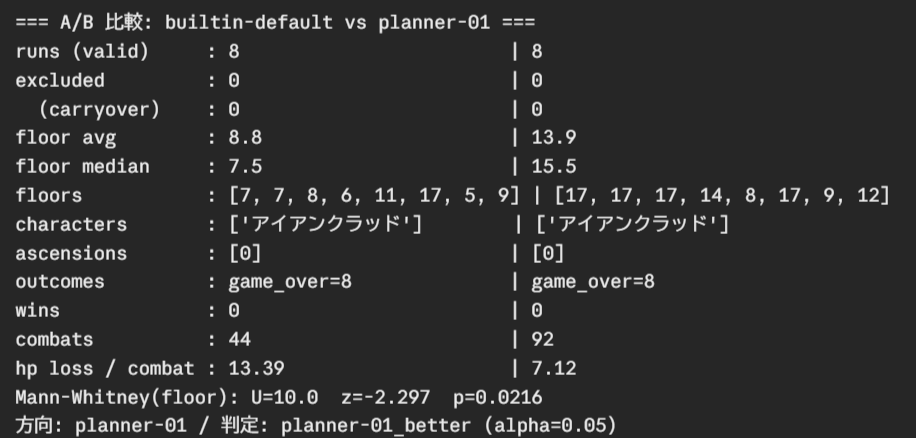
Swing the numbers however I liked and nothing budged — yet just fixing the order of play halved the damage taken and got it reliably to the doorstep of the first major boss.
The lesson here is clear. What was flat a moment ago wasn’t because the bot had hit its limit — it was because I’d been pulling the wrong lever. Improvements that raise the quality of play really do work. I’d almost mistaken “the numbers won’t move” for “this is the ceiling.”
The wall I still couldn’t clear
I’ll be honest. The improved version now marches happily up to the major boss. But it can’t finish that boss off.
From there I made five more moves toward “building a stronger deck”: buy strong cards, cut dead cards, spend upgrades wisely, play big cards earlier. But none produced a clear effect. Even the most promising one beat the boss only about 2 times in 8.
And that crucial first major boss: beatable with good luck, but not reliably (roughly 1–2 times in 8). To clear this game to the end, you have to beat each area’s major boss — three of them, back to back. If you only win one in five attempts, the odds of three in a row are under 1%. There’s simply no reaching it.
In other words, an approach that “just follows fixed rules” has a hard ceiling. Getting past it would seem to need machinery that thinks further ahead — computing several moves out, or letting an AI judge the situation itself.
The biggest finding: what corrupts an experiment is usually a bug on the measuring side
Lastly, the thing I learned most in those 12 hours. Half of the improvement work was, in fact, “keeping the experiment itself trustworthy.”
A bug that quietly corrupted the results was lurking on the measuring side. For instance: the program would get one card’s play wrong, the action would spin uselessly, and that match would freeze. That “accident” of a match was slipping into the tally as a “success that reached floor 13”. You can’t correctly measure whether anything got stronger like that.
Until I stamped out measurement mistakes like this, I couldn’t tell “the improvement didn’t work” apart from “I wasn’t measuring correctly in the first place.”
In the end, the most valuable thing I came away with may have been less the individual tactics than “a measurement setup I can trust.”
One-line takeaway: when adjusting the config numbers does nothing, that isn’t necessarily “the limit of the AI.” Rebuilding the “play procedure” itself is what brought the first win. Although, honestly, there’s still a wall beyond that — and past it you need a different approach that thinks ahead.
20 years of coding; still a hands-on engineering manager and data scientist, specializing in data platforms and AI workflows. This piece was written while having Claude Code autonomously run the improvement loop.