Slay the Spire 2 のAIを12時間回し続けて分かった「効くレバー・効かないレバー」
Slay the Spire 2 はカードを選んで敵と戦い、上の階(フロア)へ登っていく、運の要素が強いゲームです。これを人の代わりに自動で遊んでくれるプログラム(bot)にしました(前回は、Python からゲームを観測・操作する土台づくりでした)。「どうすればもっと強くなるか」の改良は AI(Claude Code)に任せて約12時間ぶっ通しで回し続けました。
強くするために、いじれそうな“レバー”はいくつもあります。防御の固さ、カードの選び方、道具の使い方……。どれを引けば本当に強くなるのか。12時間ぶんの結論を先に3つだけ書きます。
- 設定の数字をいじっても、強さはまるで変わりませんでした。 思いつくかぎり試して、全部が横ばい。
- 効いたのは、たった一つ。「1ターンの戦い方の手順」を作り直したときだけです。 これで、1回の戦闘で受けるダメージがほぼ半分になり、進める深さが倍になりました。
- それでも、最初の大ボスを安定して倒す壁は越えられませんでした。 ここから先は、たぶん別のやり方が要ります。
まず、「強くなった」をどう確かめたか
bot を改良したとき、「前より強くなった」とどうやって確かめるのか。これが地味に難しいところでした。
このゲームは運の要素がとても強く、まったく同じ戦い方でも、登れる階は毎回バラバラです。たまたま上まで行けることもあれば、序盤で力尽きることもある。しかも、この時点の bot はまだ一度も勝てていません。だから「勝率」では比べられないのです。
そこで、「どこまで登れたか」で強さを測ることにしました。新しい改良版と、いまの一番強い版を交互に何十回も遊ばせて、登れた階の傾向を比べます。交互にするのは、時間帯やゲームの更新といった“その日の調子”が、どちらか片方だけに有利に働かないようにするためです。改良版がはっきり上回ったときだけ採用しました。
この“ものさし”がいい加減だと、ここから先の話は全部ただの思い込みで終わっていました。
効かなかったレバー:数字をいじっても、動かない
最初に手をつけたのは、設定の数字でした。たとえば「HPがこのくらい減ったら、攻撃より防御を優先する」——その“境目”の数字を上げたり下げたり。ほかにも、強いカードをどれだけ高く評価するか、道具を使う条件をゆるめるか。思いつくものを6種類ためしました。
結果は全部、横ばい。極めつけは、良さそうな調整を“全部のせ”したときです。なんと、もとの戦い方と1ミリも変わりませんでした(統計で見ても「完全に同じ」と出ました)。
なぜ動かないのか。プレイの記録を見ていくと、数字では直しようのない“下手さ”が次々に見つかりました。
- 強力な道具(ポーション)を一度も使わずに負ける。 「20ダメージ」や「ガード+12」のような切り札を2〜4個も握ったまま、毎回そのまま力尽きていました。
- ボス相手に守ってばかりで攻めきれない。 攻撃に集中すれば削りきれる場面でも、防御カードに手をとられて、先に自分が倒れる。
- 休憩所ではいつも一番上の選択肢を選ぶだけ。 「カードを鍛える」と「HPを回復する」を状況で選び分けず、何度試しても機械的に同じ選択。
数字をいくらいじっても、こうしたそもそもの下手さは直りません。一つひとつの機能を足し算しても、「ずっと削られ続ける」という根っこは変わらなかったのです。
効いたレバー:数字ではなく、「戦い方の手順」を作り直す
ここで発想を変えました。いじるのは数字じゃない。1ターンの中で「何を、どの順番でやるか」そのものを組み直したのです。
考え方は拍子抜けするほど素直です。
- まず、倒せる敵がいたら先に倒す。(こちらが受けるダメージのもとを1つ減らす)
- 次に、相手の攻撃を“ちょうど防げるぶんだけ”守る。(守りすぎない)
- 余った力は全部攻撃にまわす。
要は「必要なぶんだけ守って、あとは殴る」。たったそれだけです。これが初めてはっきり勝った改良でした。
- 1回の戦闘で受けるダメージ:平均13.4 → 7.1(ほぼ半分)
- 進める深さ(真ん中の値):7.5 → 15.5(倍)
- 統計で比べても、「偶然では説明できない差」と出ました。
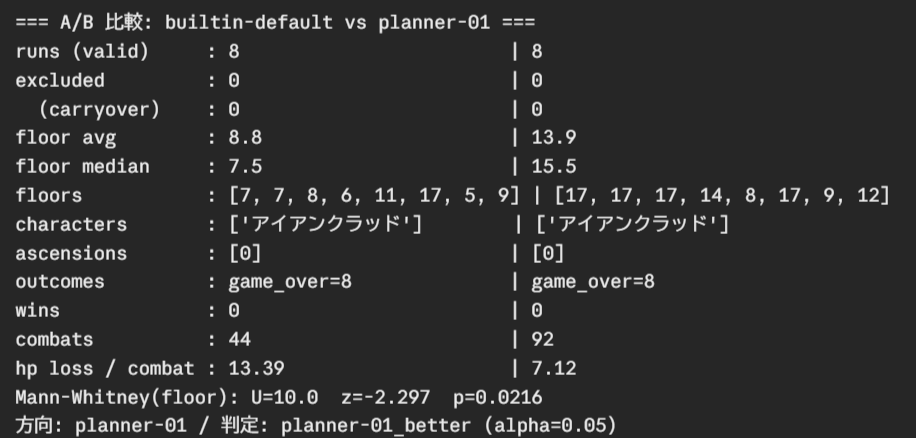
数字をいくら振っても動かなかったのに、戦い方の順番を正しただけで受けるダメージが半分になり、最初の大ボスの前まで安定してたどり着けるようになりました。
ここでの教訓ははっきりしています。さっきまで横ばいだったのは、bot が弱かったからではなく、“いじる場所”がズレていたから。戦い方の質を上げる改良はちゃんと効くのです。数字が動かないのを「もう限界だ」と取り違えてはいけませんでした。
それでも、越えられない壁
正直に書きます。改良版は大ボスの前まで元気にたどり着くようになりました。でも、そのボスを倒しきれない。
そこから「もっとデッキを強くする」方向で、さらに5つ手を打ちました。強いカードを買う、いらないカードを捨てる、強化を賢く配る、大技を早めに出す——。けれど、どれもはっきりした効果は出ませんでした。一番惜しかったものでも、ボスを倒せるのは8回に2回ほど。
そして肝心の最初の大ボスは、運がよければ倒せるけれど、安定しては倒せない(だいたい8回に1〜2回)。このゲームを最後までクリアするには、各エリアの大ボスを3体、連続で倒さなければなりません。1体を5回に1回しか倒せないなら、3連続できる確率は 1%未満。届きようがないのです。
つまり、「決められたルールで動くだけ」のやり方には硬い天井があります。これを超えるには、もっと先を読んで考える仕組み——数手先を計算したり、AIに状況そのものを判断させたり——が要りそうです。
一番の発見:実験を狂わせるのは、たいてい“測る側”のバグ
最後に、12時間でいちばん勉強になったことを。改良の作業の半分は、実は「実験そのものを信じられる状態に保つこと」でした。
結果を静かに狂わせるバグが測る側にひそんでいたからです。たとえば——あるカードの出し方をプログラムがまちがえて、操作が空回りし、その試合がフリーズ。その“事故”の試合が、「フロア13まで進んだ成功例」として集計に紛れ込んでいました。これでは、強くなったかどうかなど、正しく測れません。
こうした計測ミスを潰すまで、「改良が効かなかった」のか「そもそも正しく測れていなかった」のか、区別がつきませんでした。
結局、手に入れた一番の財産は、個々の戦い方そのものよりも「信用できる実験のしくみ」のほうだったのかもしれません。
持ち帰り一文:設定の数字を調整しても効かないとき、それは「AIの限界」とは限りません。「戦い方の手順」そのものを作り直すことが、初めての勝ちを連れてきました。ただし正直、それでも越えられない壁はあって、その先には「先を読んで考える」別のやり方が必要になります。
コーディング歴20年、いまも現役で手を動かすエンジニアリングマネジャー兼データサイエンティスト。データ基盤とAIワークフローが専門です。本稿はClaude Codeに改善ループを自律で回してもらいながら書きました。