STS2ボット改善(3) 8回のA/Bテストでは何も分からない — ボス戦シミュレータを作って25分で決着させた
ボットに入れた改善が本当に効いているのか、実機で5時間テストしても分かりませんでした。そこでボス戦だけを再現する自作シミュレータに切り替えたら、25分で「効いている」と確定できました。効果がないのに偶然だけでこれほどの差が出る確率(p値)は0.0001。実機では何度やっても「判定不能」だった同じ問いに、です。
今回はボットを強くする話ではありません。強くなったかを測れるようにする話です。やってみて分かったのですが、ボットづくりの作業の半分は、ボット本体ではなく「計器」を作る作業でした。
何の話か
前回までのあらすじ: Slay the Spire 2(カードを使って戦うローグライクゲーム)を自動で遊ぶボットを、Claude Code(AIコーディングエージェント)と一緒に作っています。数値パラメータの調整は6種類試して全部横ばい、「必要なだけ防御して残りを攻撃に回す」という戦闘手順の見直しだけが効いた、というところまで書きました。
次の壁は最初の大ボスです。たどり着けるのに、倒せない。今回の主役はこの壁……の手前にある、もっと地味な壁です。「改善が効いたかどうか、そもそも判定できない」という壁です。
前段: ボスはこちらの想定の外で戦っていた
まず、過去の対戦ログからボス戦だけを64件(8勝56敗)抜き出して解剖するツールを書きました。1ラウンドごとに「実際に与えたダメージ」と「その手札で出せたはずの最大ダメージ」を見比べるものです。
最初の発見はログの中にありました。9ダメージと12ダメージの攻撃を撃ったのに、ボスのHPが173→172→171と1ずつしか減っていない。ボスには「スリップ」というバフが付いていて、最初の8回のHP損失を1に置き換えていたのです。ボットは「ダメージ効率の高い札から切る」という素直なルールで動いているので、一番高い札から順にこのシールドへ吸わせていました。スリップで無駄になったダメージは、対象24戦で平均61・最大175にのぼります。
もうひとつの発見は、ログの外にありました。ボットのプレイ画面を眺めていたら、強打(相手の受けるダメージを50%増やす「弱体」を付けるカード)を毎回いちばん最後に撃っている。弱体を付けてから殴れば後続が全部1.5倍になるのに、殴り終わってから付けているわけです。
ところが解剖ツールの最初の版は「ボットのプレイは理論値の92%でほぼ最適」と報告していました。指摘して再検証させたら、分析の側が弱体や筋力といった状態効果を計算に入れていませんでした。直すと効率は82.5%に下がり、弱体の恩恵を受けたダメージは全体の11%しかないことが分かりました。強打を切った43ラウンドのうち51%で、素の攻撃が先に出ていました。
ボスごとに事情も違いました。解剖ツールが出した表がこれです(実ダメ/R=1ラウンドに実際に与えたダメージ、必要ダメ/R=勝つために必要だったダメージ)。
| ボス | 戦績 | 敗戦の効率 | 実ダメ/R | 必要ダメ/R | スリップ税 |
|---|---|---|---|---|---|
| ヴァントム | 3勝21敗 | 0.90 | 13.4 | 28.3 | 平均64 |
| 儀式の獣 | 5勝12敗 | 0.68 | 19.4 | 36.9 | 0 |
| 血族の司祭 | 0勝23敗 | 0.87 | 23.7 | 55.2 | 0 |
読み方はこうです。儀式の獣は効率0.68で、出せたはずの火力を出し切れていない=プレイで勝てる余地がある。ヴァントムは効率0.90と高いのにスリップ税が重い=札の切る順番の問題。血族の司祭は必要ダメージが現デッキの2倍超(実は307HPの長期戦)=そもそもデッキの地力不足。同じ「負け」でも処方箋が三者三様だと分かります。
ここで得た教訓がのちのシミュレータ設計を決めます。計器がゲームのルールを知らないと「最適です」と誤読する。
直したのに、効いたかどうか分からない
並び順のルールはすぐ実装できました。弱体を付けてから殴る、スリップ中は安い札から切ってシールドを剥がす、の2点です。
問題はここからでした。実機のA/Bテスト(改善前と改善後のボットを8回ずつ走らせて到達フロアを比べる)は1回につき約1時間かかります。結果は「判定不能」(p=0.63)。ドラフト(カード取得)の改善と束ねてさらに2回、合計16ランずつまで増やしてもp=0.47。統計的には何も言えません。
一方で、ボス戦の中身は明らかに変わっていました。改善版はボスの残りHP 8・27・30という惜敗を3連発したのです。それまでの負けは残りHP100以上の大敗ばかりでした。あと一押しまで来ているのに、それを数字で証明できない。
原因を整理すると、実機テストは構造的にこの問いに向いていませんでした。
- 評価指標の「到達フロア」はボスの壁(17階)で頭打ちになり、それ以上の差はボスを倒さない限り出ない
- ボス戦自体が1回のテストで2〜4回しか発生せず、どのボスを引くかも運
- 撃破率の差を検出するには概算で片側50回以上のボス戦が必要で、実機なら積算10時間を超える計算
ここで改善ループをいったん止めました。ボットをいじり続けるのではなく、先に計器を直すことにしました。
シミュレータの設計 — 決めたことは3つ
ボス戦だけをプログラム内で再現して、何千回でも戦わせる。作るにあたって決めたことは3つです。
1. ボットの判断コードは1行も書き換えない。 シミュレータの側が、ゲームのMOD(改造プログラム。ボットはこれ経由でゲームの状態をJSONというデータ形式で受け取ります)とまったく同じ形式の状態データを吐くようにしました。本物の判断コードがそれを読み、本物の行動を返し、シミュレータが結果を計算する。こうすると「シミュレータでの強さ」と「実機での強さ」が同じコードの話になります。テスト用に書き直した別物を測ってしまう事故を、構造的に防げます。
2. 敵のAIは書かない。 ボスの行動ルールを推測して実装すると、スリップのときと同じ轍を踏みます。代わりに、過去ログから敵の行動列(ラウンドごとに何ダメージの攻撃を何回するか)を90戦ぶん採掘して、そのまま台本としてリプレイすることにしました。実測の再生なら、こちらの推測が入り込む余地がありません。
3. 運をペアで殺す。 比較したい2つのボットに、同じデッキ・同じ敵の台本・同じ乱数を与えて戦わせます。すると両方勝った試合と両方負けた試合は「引き分け」として消え、結果が割れたペアだけが残ります。あとは「割れたとき、どちらが勝つことが多いか」を数えるだけ(符号検定という古典的な方法です)。デッキの強弱やボスの引きといった運が、引き算で完全に消えます。
カードの効果は説明文を読んで数値化します(「8ダメージを与える。弱体2を付与する。」→ ダメージ8、弱体2)。読めない効果のカードは「何もしない」扱いにして、何回プレイされたかを正直に数えておきます。
計器の校正 — どこまで本物に近いか
シミュレータは作って終わりではなく、本物とどれくらいズレるかを測ってから使います。3段階で答え合わせをしました。
| 検証 | 結果 |
|---|---|
| 1手ごとの与ダメージ予測(1913手) | 91.5%が誤差±3以内 |
| 敵ターンの被ダメージ予測(515回) | 93.2%が誤差±3以内 |
| 戦闘丸ごとの勝率(ボス別) | ヴァントム: シム11.8% vs 実測8.6% / 血族の司祭: 2.8% vs 0% / 儀式の獣: 2.3% vs 19.2%で大きくズレ |
儀式の獣だけ大きく外れた理由ははっきりしていて、このボスに勝った実デッキは「盤石」「ジャグリング」のような特殊カード(それぞれ1デッキしか持っていない固有のエンジン)に頼っており、シミュレータがそれを未実装だからです。
それでも比較の道具としては使えます。比べる2つのボットは同じ欠けたエンジンで戦うので、欠けの影響は両側に等しくかかり、差を取れば消えるからです。使い方のルールはこうなります: 絶対の勝率は信用しない。順位だけ読む。
25分で出た答え
校正を終えて、実機で判定できなかった問いを掛けました。「弱体を先に付け、スリップ中は安い札から切る」並び順ルールは効いているのか?
4000ペア(8000戦)を約25分で消化して、答えは「効いている」(p=0.0001)。撃破率は7.5%→8.8%でした。
uv run python -m game_api.sim.arena --from-report logs/sim-arena/report.json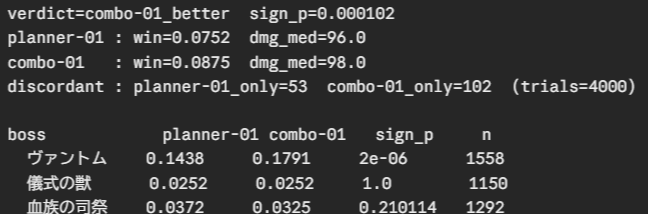
内訳がきれいでした。改善が出たのはスリップを持つボス(ヴァントム)だけで、撃破率14.4%→17.9%(p=0.000002)。スリップ対策として設計したルールが、スリップを持つボスでだけ効いている。他の2ボスでは差なし — これも解剖時の予測(弱体はスリップ中は無効、血族の司祭は307HPの長期戦でそもそもデッキの火力不足)と一致します。設計と計測が噛み合った瞬間です。この1日でいちばん意外だったのは、実機5時間で出なかった答えが本当に25分で出てしまったこと、それ自体でした。
速度の内訳は単純です。実機はボス戦1回に数分、シミュレータは1戦あたり約0.2秒。判断しているコードはどちらも同じものです。
限界と、次にやること
正直な注意書きです。
- この計器はドラフトの差を測れません。 同じデッキで戦わせる設計なので、戦闘中の判断の差だけが出ます。デッキ構築の良し悪しは別の方法で測る必要があります
- 絶対の勝率は実機より控えめに出ます(特に儀式の獣)。未実装カードのぶんです
- そして肝心のボスは、まだ安定して倒せていません。シミュレータ上の撃破率はボスにより2〜18%です
次はこの計器で、実機では判定不能のまま棚上げしていた別の戦闘ルール(ボス戦で防御を捨てて殴り切る「レースモード」)に決着をつけます。デッキ構築の側は、カードの説明文を読んで取捨を判断させるLLM(大規模言語モデル)の出番だと考えています。
筆者: トモキ — コーディング歴20年、いまも現役で手を動かすエンジニアリングマネジャー兼データサイエンティスト。データ基盤とAIワークフローが専門。